隨著信息技術的飛速發展,大數據已成為推動社會進步和企業創新的核心驅動力。大數據采集作為整個大數據處理流程的基礎環節,其方法的科學分類與網絡技術的開發應用顯得尤為重要。本文將系統性地梳理大數據采集方法的主要分類,并結合網絡技術開發的最新進展,探討各類方法的實現原理、應用場景及其技術挑戰。
一、大數據采集方法的主要分類
1. 按數據來源分類
- 結構化數據采集:主要涉及數據庫系統、數據倉庫等結構化存儲環境,通過SQL查詢、ETL工具(如Apache NiFi、Talend)等方式實現數據提取。
- 半結構化數據采集:針對XML、JSON、日志文件等半結構化數據源,通常采用解析器(如Jackson、Gson)或專用工具(如Logstash)進行采集。
- 非結構化數據采集:包括文本、圖像、音頻、視頻等,需借助自然語言處理(NLP)、計算機視覺等技術,結合爬蟲工具(如Scrapy、Apache Nutch)或API接口實現采集。
2. 按采集方式分類
- 主動采集:通過爬蟲、傳感器網絡、API調用等方式主動獲取數據。例如,網絡爬蟲可采集網頁內容,IoT設備可實時采集環境數據。
- 被動采集:依賴于日志記錄、監控系統或用戶行為追蹤工具(如Google Analytics)被動接收數據流,常用于網站流量分析或用戶行為研究。
3. 按實時性分類
- 批量采集:適用于非實時場景,數據按周期(如每日、每周)批量收集,常見工具有Apache Sqoop、Hadoop DistCp。
- 實時采集:通過流處理技術(如Apache Kafka、Apache Flume)實現數據的即時采集與傳輸,適用于金融交易、物聯網監控等對時效性要求高的領域。
4. 按數據規模分類
- 小規模采集:針對局部數據源,如單機數據庫或文件系統,可通過腳本或輕量級工具實現。
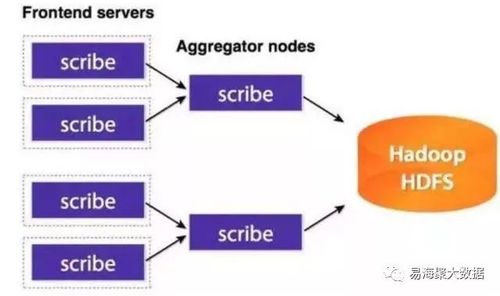
- 大規模分布式采集:面向海量數據源,需采用分布式架構(如Apache Spark、Hadoop HDFS)和集群管理工具(如Kubernetes)以提升采集效率與可靠性。
二、網絡技術開發在大數據采集中的應用
網絡技術開發為大數據采集提供了強大的支撐,主要體現在以下幾個方面:
1. 高性能網絡協議
- 采用HTTP/2、QUIC等現代協議優化數據傳輸效率,減少延遲與帶寬消耗。
- 利用WebSocket實現全雙工通信,支持實時數據流的持續采集。
2. 分布式網絡架構
- 基于微服務架構設計采集系統,實現模塊化部署與彈性擴展。
- 使用負載均衡技術(如Nginx、HAProxy)分散采集壓力,確保系統高可用性。
3. 安全與隱私保護
- 通過TLS/SSL加密傳輸數據,防止中間人攻擊。
- 結合OAuth、API密鑰等認證機制,保障數據采集的合法性與安全性。
4. 邊緣計算與5G技術
- 利用邊緣計算節點在數據源頭進行預處理,降低中心服務器的負載。
- 5G網絡的高速率與低延遲特性為移動端大數據采集(如智能設備、車聯網)提供了新的可能性。
三、技術挑戰與未來趨勢
盡管大數據采集方法不斷豐富,網絡技術持續進步,但仍面臨數據異構性、實時處理能力、隱私合規等挑戰。隨著人工智能與區塊鏈技術的融合,智能采集代理與去中心化數據市場可能成為新的發展方向。聯邦學習等隱私保護技術將進一步提升數據采集的合規性與安全性。
大數據采集方法的科學分類與網絡技術開發的緊密結合,不僅提升了數據獲取的效率與質量,也為各行業的數據驅動決策奠定了堅實基礎。開發者需持續關注技術演進,靈活運用各類工具與架構,以應對日益復雜的數據環境。