在當今信息爆炸的時代,如何從海量網絡新聞中高效提取、分析并呈現有價值的信息,成為了一個重要的技術課題。本文將以開發者“zgz102928”在CSDN博客分享的經驗為基礎,探討如何利用MyEclipse集成開發環境,結合Tomcat服務器、MySQL數據庫和JSP動態網頁技術,構建一個基于網絡爬蟲技術的網絡新聞分析系統。
一、系統架構與技術選型
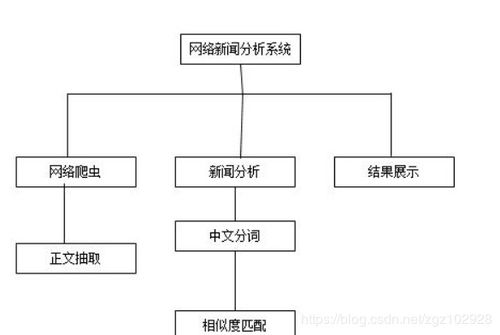
本系統的核心目標是實現一個能夠自動抓取、存儲、分析和展示網絡新聞的Web應用。其技術架構主要分為三層:
- 數據采集層(網絡爬蟲):這是系統的“觸手”。我們使用Java語言開發網絡爬蟲程序,利用Jsoup或HttpClient等開源庫,模擬瀏覽器行為,定向抓取目標新聞網站(如新浪、網易、騰訊新聞等)的HTML頁面。爬蟲需要精心設計,遵守Robots協議,并包含URL管理、頁面解析、去重和異常處理等模塊。
- 數據存儲與處理層:這是系統的“大腦”與“倉庫”。
- MySQL數據庫:負責結構化存儲爬取到的新聞數據。通常設計數據表來存放新聞的標題、正文、來源、發布時間、URL、關鍵詞等核心字段。數據庫設計需考慮查詢效率和數據關系。
- Java業務邏輯:在MyEclipse中編寫Java類(如Servlet、JavaBean),負責處理爬蟲調度、數據清洗(如去除HTML標簽、過濾廣告)、關鍵詞提取、簡單的情感分析或主題分類等分析任務,并將處理后的數據存入數據庫或提供給展示層。
- 數據展示層(Web應用):這是系統的“面孔”。
- JSP動態頁面:用于生成用戶交互界面。可以創建新聞列表頁、詳情頁、關鍵詞分析結果頁、趨勢圖表頁等。
- Tomcat服務器:作為JSP和Servlet的運行容器,接收用戶請求,調用后臺Java邏輯,從數據庫獲取數據,并動態生成HTML頁面返回給用戶瀏覽器。
二、開發環境搭建與核心步驟
- 環境準備:在MyEclipse中配置Java開發環境,集成Tomcat服務器,并建立與MySQL數據庫的連接(通常通過JDBC驅動)。
- 數據庫設計:在MySQL中創建數據庫(如
news<em>analysis)和核心表(如news</em>article表)。
- 爬蟲模塊開發:
- 創建一個Java項目,引入Jsoup等依賴庫。
- 編寫爬蟲主類,實現從種子URL開始,通過鏈接提取進行廣度或深度優先遍歷。
- 使用Jsoup的CSS選擇器或DOM方法精準定位并提取新聞頁面的標題、正文等元素。
- 將提取的數據封裝為對象,并通過JDBC持久化到MySQL數據庫。
- Web應用開發:
- 創建一個Web Project。
- 編寫Servlet(如
NewsListServlet)來處理用戶請求(如查看新聞列表),調用Service層方法從數據庫查詢數據。
- 編寫JSP頁面(如
newsList.jsp),使用JSTL或EL表達式循環展示Servlet傳遞過來的新聞列表數據。
- 可以開發更復雜的分析頁面,例如通過查詢數據庫統計不同來源的新聞數量,并使用JFreeChart等庫生成圖表在JSP中展示。
- 集成與部署:將爬蟲模塊作為后臺任務(可設置為定時任務,如使用Quartz調度框架)集成到Web項目中,或將爬蟲作為獨立服務。將整個Web項目部署到Tomcat并啟動。
三、技術要點與挑戰
- 爬蟲效率與禮貌性:需設置合理的請求間隔,避免給目標服務器造成過大壓力,防止IP被封禁。
- 反爬蟲策略應對:部分網站會采用JavaScript渲染、驗證碼、動態請求參數等方式反爬,可能需要結合Selenium等工具進行動態頁面抓取,或分析Ajax請求接口。
- 數據清洗與分析深度:新聞正文提取需要處理復雜的HTML結構,去除無關內容。基礎的分析可以基于關鍵詞詞頻統計,更深入的分析可能需要引入自然語言處理(NLP)技術,如使用開源庫進行情感分析、實體識別或主題建模。
- 系統性能:隨著數據量增長,數據庫查詢和頁面響應速度可能成為瓶頸,需要考慮索引優化、分頁查詢及緩存機制(如Redis)。
四、
通過MyEclipse、Tomcat、MySQL和JSP這一經典的Java Web開發技術組合,我們可以構建出一個功能完整的網絡新聞分析系統原型。該系統實現了從數據采集、存儲、處理到可視化展示的全流程。開發者“zgz102928”的實踐為初學者提供了一個清晰的學習路徑。該系統可以進一步拓展,例如引入更智能的分析算法、實現實時爬取與預警、或構建響應式前端界面,從而提升其分析能力和用戶體驗。此項目不僅鞏固了Java Web開發技能,也是踏入數據分析與信息檢索領域的一個絕佳實踐。